X
X
XXXXXXXXXXXXXXXX
ROACH DNA- WELLCOME DNA RESEARCH CENTER
XXXXXXXXXXXXXXXXXXXX
X
|
10:45 PM (4 minutes ago)
| |||
x
x
x
XX
X

X
Xx
x
x
xX
https://www.nature.com/news/where-in-the-world-could-the-first-crispr-baby-be-born-1.18542 X
https://www.nature.com/news/biohackers-gear-up-for-genome-editing-1.18236
X
https://www.nature.com/news/alien-dna-makes-proteins-in-living-cells-for-the-first-time-1.23040
X
X
Hi
I have a serious question.
I have done some internet research on google; & by "armchair genealogy"- traced my ancestry possible back to early 11th - or 10th century Normandy; wales; Irish; America- bloodline from ROCH CASTLE-; VISCOUNT OF FERMOY IN IRELAND--
so I have been hearing of all the mail order DNA testing genealogy web sites-
so based on all this "armchair research"- online; and some done the old fashioned method by my Grandfather- I have a high probability to believe I "MAY" be related to Princess diana; William & Harry- among others.
I have been joing with my friends- (half)- that I could be related BLOODLINE WISE - to the "bloody King of England"- or the King of Bloody England "
- interchangeably..
- So- What if I REALLY AM?-DNA BLOODLINE WISE?- ROCH; ROCHE; ROACHE ETC?-
My family "coat of arms"; Heraldry- is a red shield with three argent fishes on them- ( easy to google)-
What can you do to help me find out this potentials very intriguing question & answer?-
I may as well get a DNA test as close to the IRELAND; ENGLAND WALES NORMANDY- &* EAST- ancestry from a scientific research facility that is as close to the source as it gets?
also- to find out any DNA; or potentially hazardous health conditions that run in my bloodline?-
I was just reading about a preponderance of blood type A+- of which I am; My Mother is B+ with a strange anomaly- to COLD" ANTIBODIES"- - Im not certain of the details-
Anyway- I am totally serious in this inquiry- but im also just a fund dude too--
so- can you send me a DNA TEST KIT- and work your WIZARDRY on it- and lets see what turns up?
seriously- what if i AM the rightful "bloody King of england"?-
- by DNA & bloodline? or at the very least- as an interesting trivia quirk of history actually really related to the two Princes?- who knows- it may be enough to get myself knighted; or invited to the upcoming royal wedding?-
so go ahead- smirk- and shake your heads but after afternoon tea- WHAT IF?- so are you all up for an interesting QUEST?-
so I can tell my friends int eh bar- YES- IT'S GOOD TO BE THE KING..
but seriously-
thank you for you patience and good humor in this quixotic adventure..
David Christopher Roach/Roche/Roache/ de La Roche
(named for St David- for the record)
My grandfather was named Giraldus- for giraldus of cambria- an ancient Wales Historian- so-
Adam de la Rupe; Pill Priory; Roch castle-
David Roche- first viscount of Fermoy-
I have a serious question.
I have done some internet research on google; & by "armchair genealogy"- traced my ancestry possible back to early 11th - or 10th century Normandy; wales; Irish; America- bloodline from ROCH CASTLE-; VISCOUNT OF FERMOY IN IRELAND--
so I have been hearing of all the mail order DNA testing genealogy web sites-
so based on all this "armchair research"- online; and some done the old fashioned method by my Grandfather- I have a high probability to believe I "MAY" be related to Princess diana; William & Harry- among others.
I have been joing with my friends- (half)- that I could be related BLOODLINE WISE - to the "bloody King of England"- or the King of Bloody England "
- interchangeably..
- So- What if I REALLY AM?-DNA BLOODLINE WISE?- ROCH; ROCHE; ROACHE ETC?-
My family "coat of arms"; Heraldry- is a red shield with three argent fishes on them- ( easy to google)-
What can you do to help me find out this potentials very intriguing question & answer?-
I may as well get a DNA test as close to the IRELAND; ENGLAND WALES NORMANDY- &* EAST- ancestry from a scientific research facility that is as close to the source as it gets?
also- to find out any DNA; or potentially hazardous health conditions that run in my bloodline?-
I was just reading about a preponderance of blood type A+- of which I am; My Mother is B+ with a strange anomaly- to COLD" ANTIBODIES"- - Im not certain of the details-
Anyway- I am totally serious in this inquiry- but im also just a fund dude too--
so- can you send me a DNA TEST KIT- and work your WIZARDRY on it- and lets see what turns up?
seriously- what if i AM the rightful "bloody King of england"?-
- by DNA & bloodline? or at the very least- as an interesting trivia quirk of history actually really related to the two Princes?- who knows- it may be enough to get myself knighted; or invited to the upcoming royal wedding?-
so go ahead- smirk- and shake your heads but after afternoon tea- WHAT IF?- so are you all up for an interesting QUEST?-
so I can tell my friends int eh bar- YES- IT'S GOOD TO BE THE KING..
but seriously-
thank you for you patience and good humor in this quixotic adventure..
David Christopher Roach/Roche/Roache/ de La Roche
(named for St David- for the record)
My grandfather was named Giraldus- for giraldus of cambria- an ancient Wales Historian- so-
Adam de la Rupe; Pill Priory; Roch castle-
David Roche- first viscount of Fermoy-
DNA-
X
X


X
RE:- you go far enough back-we're all related- Im certain that is true- the Earth is a closed loop system- so- scientifically speaking- from evolution- there were originally two first homo sapiens- U have read National Geographic magazines saying humans are from east-central Africa ; and propagated throughout the planet from there-
I use the analogy GENE POOL- LIKE A SWIMMING POOL-
all the human DNA is the water- from when time began; and the swimming pool- is the Earth
so- if you have several people- each with a beaker of colored water- various colors- white- black brown red yellow- and any colors in between-
you blow a whistle- & they all pour their beakers in the swimming pool water- at first- there will be patches of the various colors of water- but after the water is allowed to circulate & mix for a sufficient period- say 24 hours- the various colors of water will be indistuinguishable- like you said- completely intermixed- & all the different colored water "marker dyes"- will be the same-
that we humans- are all the same- except for tiny variations- & "mutations"-
Another "DNA experiment"- I like to use- is a simple cup of coffee; and a glass of cream- coffee being dark brown/black in color- and milk- of course being white-
you mix them together- and the color is some medium in between- did the milk turn black? did the coffee turn white?-
but nevermind- it sure is good in the morning-
or TEA & MILK- - Brits like TEA- right?
heres a humorous term- "INBRED NOBILITY"
referring the the European royal families in the 18th 19th 20th century- the Present Queen of England; Prince Charles & family- are all related to various-
pre-WW2 mostly- ancestry-- and other family members
the various Kings Queens; etc- of England & the other dynastys-
here in the USA-"INBREDS"- is a derisive term- like marrying your cousin in a rural town-
We have this In our own region- with the AMISH- they are a very tight knit community& their gene pool; DNA- is strongly intermixed-
I suppose like the ones of rural isolated areas of the UK Island-
anyway- in the DOG breeding /dog show business- Purebred dogs are valuable- unless that breed has certain traits that are undesirable- then you are only exaggerating them- until your dog breed is a bunch of mad dogs-lol-
Cattle; sheep; other live stock- too-
Of Course Im very very IRISH- so Im acquainted with Potato Famine; how all the Potatoes in Ireland were all genetically identical; so when the potato blight stuck- all the potatoes died- creating the 19th century IRISH DIASPORA.
ditto the Black Plague or the smallpox; or various influenza epidemics- many die; and those who survive- somehow have Immunity- which is passed on-
Evolution-
well- Im Irish; Welsh; Norman French; German; & Nordic; & central european as it gets- Middle age white guy-
these DNA Profiles will show various propensitys to various health issues.
I wish babies were DNA "fingerprinted at birth; and the same for criminals--
a notable example of that would be If CSI London- had DNA technology- we would all know who Jack the Ripper was; andhow DNA is proving to catch so many dangerous Felons--
I know it can be used for bad motives- but the good of HUMAN DNA RESEARCH IS A VERY NOBLE & IMPORTANT ENDEAVOR -
like why some people are blue eyed; some are green eyed, many are brown eyed- ; and some are various colors in between-
My mothers favorite saying was "Its all shades of gray"-
meaning nothing is certain-
the 144,000 humans in the 12 tribes of Israel- Imagine what a treasure trove of DNA and human knowledge THAT would be-Knowing Moses; abraham; or even Jesus Mary & Josephs DNA was?-
the DA VINCI CODE- was about that; & I had seen a couple TV shows about how after the crucifixion of Jesus- or how he faked his death; and escaped; or a pregnant mary magedelen- ; along with Mary ; and Joseph- escaped Israel- across the mediterranean- to france; and England- lots of churches- the one- Mary magdalene- that Harry & his GF were just at-recently-
then we have King Arthur legends too-
interestingly- there is a village- in Wales near enough to Roch Castle Pembrokeshire Coast National Park called MERLIN'S BRIDGE- West Havfordshire-
well- I dont get out much; so I spend a lot of time online- looking up this sort of stuff; and frankly- most of the people here in my hometown are incredibly shallow about this sort of topic; except for the parts of "master race; pure bred white people; etc- im like swell- here we go again-
even that jackass in our presidential white house- is the same mentality- because if we are all the same- DNA wise- well- then obviously- hes calling himself & his own INBRED NOBILITY- here in the USA- the same vulgar term--
TEE HEE!
I want to checkout your web site; and learn more about YOUR OWN research projects- and such- go straight to the DNA family tree ROOTS-
Merry Olde England; Ireland, France *& such
ARE THERE ANY RESEARCH INSTITUTES LIKE YOURS IN FRANCE OR GERMANY OR ITALY; SWITZERLAND; NETHERLANDS; BELGIUM?
- again- straight to the source-
the INTERNET & SOCIAL MEDIA SURE IS CONVENIENT & EASY -isnt it?
David Christopher Roach
Xxx
David Christopher Roach Burke’s Peerage- ive read google excerpts of this- ROCHES; ROACH'S ROACHE'S LA ROCHES DE LA ROCHES
hmm- from the link you referred me to THX!
David Christopher Roach Burke’s Peerage- ive read google excerpts of this- ROCHES; ROACH'S ROACHE'S LA ROCHES DE LA ROCHES
hmm- from the link you referred me to THX!
X
X
The advent of cheap genetic sequencing has given birth to a burgeoning ancestry industry. But before you pay to spit in a tube, let me give you a few facts for free
X
Sometimes I get asked if I’m related to the great physicist Ernest Rutherford. His discoveries about the atomic nucleus gave birth to physics in the 20th century. He is the father of nuclear physics, with labs and atoms named after him.
I’m not related to him. I can reveal however that I am a direct descendent of someone of similar greatness: Charlemagne, Carolingian King of the Franks, Holy Roman Emperor, the great European conciliator. Quelle surprise!
But we are all special, which means none of us are. If you’re vaguely of European extraction, you are also the fruits of Charlemagne’s prodigious loins. A fecund ruler, he sired at least 18 children by motley wives and concubines, including Charles the Younger, Pippin the Hunchback, Drogo of Metz, Hruodrud, Ruodhaid, and not forgetting Hugh.
This is merely a numbers game. You have two parents, four grandparents, eight great-grandparents, and so on. But this ancestral expansion is not borne back ceaselessly into the past. If it were, your family tree when Charlemagne was Le Grand Fromagewould harbour more than a billion ancestors – more people than were alive then. What this means is that pedigrees begin to fold in on themselves a few generations back, and become less arboreal, and more web-like. In 2013, geneticists Peter Ralph and Graham Coop showed that all Europeans are descended from exactly the same people. Basically, everyone alive in the ninth century who left descendants is the ancestor of every living European today, including Charlemagne, Drogo, Pippin and Hugh. Quel dommage.
With the advent of cheap genetic sequencing, the deep, intimate history of everyone can be revealed. We carry the traces of our ancestors in our cells, and now, for the price of a secondhand copy of Burke’s Peerage, you can have your illustrious past unscrambled. Plenty of companies have emerged that provide this service, such as23andMe and Ancestry DNA. Spit in a test tube, and they will match parts of your DNA with people from all over the world. The results are beguiling, but don’t necessarily show your geographical origins in the past. They show with whom you have common ancestry today.
People love discovering that they’re a bit Viking, or a bit Saracen. This is big business nowadays, and some companies spin fabulous yarns about your forebears as marketing devices. I’ve been making a documentary for Radio 4 on what genetics can and can’t tell you about ancestry, and examining some of the more outlandish claims that some ancestry businesses make. One company offered a service whereby it would tell you the precise village location of your genetic ancestry 1,000 years ago. It’s a peculiar thing to claim, as you will have thousands of ancestors 1,000 years ago, and I’m pretty sure they won’t have all come from the same village. Their algorithm clearly needed some work: it placed the genetic origin of one paying customer in the depths of the Humber estuary.
The truth is that we all are a bit of everything, and we come from all over. If you’re white, you’re a bit Viking. And a bit Celt. And a bit Anglo-Saxon. And a bit Charlemagne. This is not to disparage genetic genealogy and ancestry. Done right, it is an immensely powerful tool for studying families and human migrations. DNA can disclose unknown cousins or parents. Further back, the past becomes dimmer, but not invisible. A dazzling, detailed analysis of the British genome last month scrutinised the history of immigration over the past 10,000 years. Expect many more studies like this from all over the world revealing all manner of dalliances from the foggy past.
Often genetic ancestry relies on the Y chromosome, which is inherited only via the paternal line, or mitochondrial DNA, which is only passed on from mothers. These make for persuasive – but often simplistic – analyses of ancestry. These two chunks of DNA make up 2% of your genome. But the other 98% has to come from somewhere too, and that is a pick-and-mix from all the rest of your ancestors.
Each subsequent generation, the contribution from an individual from your lineage becomes less. Professor Mark Thomas from University College London describes this dilution as “homeopathic”. After a few rounds of preparation, homeopathic dilutions contain no molecules of whatever the active ingredient is imagined to be. Genetic inheritance works in a similar way. Half of your genome comes from your mother and half from your father, a quarter from each of your grandparents. But because of the way the DNA deck is shuffled every time a sperm or egg is made, it doesn’t keep halving perfectly as you meander up through your family tree. If you’re fully outbred (which you aren’t), you should have 256 great-great-great-great-great-
So what does this all mean? Ancestry is messy. Genetics is messy, but powerful. People are horny. Life is complex. Anyone who says differently is selling something. A secret history is hidden in the mosaics of our genomes, but caveat emptor. If you want to spend your cash on someone in a white coat telling you that you’re descended from Vikings or Saxons or Charlemagne or even Drogo of Metz, help yourself. I, or hundreds of geneticists around the world, will shrug and do it for free, and you don’t even need to spit in a tube.
The Business of Genetic Ancestry is on BBC Radio 4, Tuesday 26 May at 11am
X
X
NATURE | NEWS
Sharing
Most Europeans share recent ancestors
Genetic sequences link far-flung populations and bear marks of historical events.
Article tools
Rights & Permissions
Alan Collins / Alamy
Any two Europeans are likely to have had a common ancestor several centuries ago.
Whether they are a Serb and a Swiss, or a Finn and a Frenchman, any two Europeans are likely to have many common ancestors who lived around 1,000 years ago. A genomic survey of 2,257 people from 40 populations finds that people of European ancestry are more closely related to one another than previously thought, and could help to bring about new insights into European history.
The first efforts to trace human ancestry through DNA relied on ‘uniparental genetic markers’ — DNA sequences from the mitochondrial genome, which is inherited through mothers, or on the Y chromosome, which men inherit from their fathers.
Those studies captured the broad strokes of human history, such as Homo sapiens' migration out of Africa less than 100,000 years ago and their subsequent colonization of Europe and Asia. But uniparental markers do little to inform more recent history, in part because they represent only a single lineage in a family tree — such as a mother’s mother’s mother, and so on.
In recent years, researchers have looked to the rest of the genome — the DNA that can come from either parent — to understand ancestry. In the latest study, population geneticists Peter Ralph, now at the University of Southern California in Los Angeles, and Graham Coop, at the University of California, Davis, looked to the entire genome to reconstruct European ancestry. Their work is published today in PLoS Biology1.
The researchers' approach relies on the way in which genes are reshuffled each generation, when an individual forms new egg or sperm cells by mixing and matching the chromosomes he or she inherited from each parent. As a result of this process, a person’s genome is made from interspersed chunks of his or her ancestors’ chromosomes. The locations where DNA sequences are swapped are different each time, so that the uninterrupted segments a person passes down become shorter with each generation. For instance, the chunks of DNA shared between first cousins are longer than those shared between second, third and fourth cousins.
Gene-sequencing companies such as 23andMe, based in Mountain View, California, use this property to connect distant cousins enrolled in their databases. Ralph and Coop looked for even more distant relatives by identifying stretches of the genome shared by people living throughout Europe. By looking at the length of these chunks, the researchers were able to determine approximately when distant cousins’ common ancestor lived.
They found common ancestors from as recently as 500 years ago mainly within populations. Older stretches of DNA, however, connected more geographically distant Europeans.
The work also uncovered genetic signatures for key events in European history, such as the migration of the Huns into Eastern Europe in the fourth century, and the later rise of Slavic-speaking people there. Present-day inhabitants of Eastern European countries share many ancestors who lived around 1,500 years ago, Ralph and Coop found. Italians, meanwhile, are connected to other European populations mainly through individuals who lived more than 2,000 years ago, perhaps as a result of the country's geographic isolation.
Studies such as this one have the potential to solve longstanding historical questions, says Coop. It has been unclear, for instance, whether the expansion of Slavic languages was driven by migration of Slavic-speaking people, cultural diffusion or both. Genetic studies “can tell us how people moved, rather than just what’s in the written record”, Coop says. John Novembre, a population geneticist at the University of Chicago in Illinois, says that the study marks “a huge step in that direction”.
- Nature
- doi:10.1038/nature.2013.12950
X
X
NEWS FEATURE
The most popular genes in the human genome

K. Krause and J. Krzysztofiak/Nature
Peter Kerpedjiev needed a crash course in genetics. A software engineer with some training in bioinformatics, he was pursuing a PhD and thought it would really help to know some fundamentals of biology. “If I wanted to have an intelligent conversation with someone, what genes do I need to know about?” he wondered.
Kerpedjiev went straight to the data. For years, the US National Library of Medicine (NLM) has been systematically tagging almost every paper in its popular PubMed database that contains some information about what a gene does. Kerpedjiev extracted all the papers marked as describing the structure, function or location of a gene or the protein it encodes.
Sorting through the records, he compiled a list of the most studied genes of all time — a sort of ‘top hits’ of the human genome, and several other genomes besides.
Heading the list, he found, is a gene called TP53. Three years ago, when Kerpedjiev first did his analysis, researchers had scrutinized the gene or the protein it produces, p53, in some 6,600 papers. Today, that number is at about 8,500 and counting. On average, around two papers are published each day describing new details of the basic biology of TP53.
Its popularity shouldn’t come as news to most biologists. The gene is a tumour suppressor, and widely known as the ‘guardian of the genome’. It is mutated in roughly half of all human cancers. “That explains its staying power,” says Bert Vogelstein, a cancer geneticist at the Johns Hopkins University School of Medicine in Baltimore, Maryland. In cancer, he says, “there’s no gene more important”.
But some chart-topping genes are less well known — including some that rose to prominence in bygone eras of genetic research, only to fall out of fashion as technology progressed. “The list was surprising,” says Kerpedjiev, now a postdoc studying genomic-data visualization at Harvard Medical School in Boston, Massachusetts. “Some genes were predictable; others were completely unexpected.”
To find out more, Nature worked with Kerpedjiev to analyse the most studied genes of all time (see ‘The top 10’). The exercise offers more than a conversation starter: it sheds light on important trends in biomedical research, revealing how concerns over specific diseases or public-health issues have shifted research priorities towards underlying genes. It also shows how just a few genes, many of which span disciplines and disease areas, have dominated research.
X
X

XX
Out of the 20,000 or so protein-coding genes in the human genome, just 100 account for more than one-quarter of the papers tagged by the NLM. Thousands go unstudied in any given year. “It’s revealing how much we don’t know about because we just don’t bother to research it,” says Helen Anne Curry, a science historian at the University of Cambridge, UK.
In and out of fashion
In 2002, just after the first drafts of the human genome were published, the NLM started systematically adding ‘gene reference into function’, or GeneRIF, tags to papers1. It has extended that annotation back to the 1960s, sometimes using other databases to help fill in the details. It is not a perfectly curated record. “In general, the data set is somewhat noisy,” says Terence Murphy, a staff scientist at the NLM in Bethesda, Maryland. There’s probably some sampling bias for papers published before 2002, he warns. That means that some genes are over-represented and a few may be erroneously missing. “But it’s not awful,” Murphy says. “As you aggregate over multiple genes, that potentially reduces some of these biases.”
With that caveat noted, the PubMed records reveal a few distinct historical periods in which gene-related papers tended to focus on particular hot topics (see ‘Fashionable genes through the years’). Before the mid-1980s, for example, much genetic research centred on haemoglobin, the oxygen-carrying molecule found in red blood cells. More than 10% of all studies on human genetics before 1985 were about haemoglobin in some way.
XX

XX
At the time, researchers were still building on the early work of Linus Pauling and Vernon Ingram, trailblazing biochemists who pioneered the study of disease at a molecular level with discoveries in the 1940s and 1950s of how abnormal haemoglobin caused sickle-cell disease. Molecular biologist Max Perutz, who won a share in the 1962 Nobel Prize in Chemistry for his 3D map of haemoglobin’s structure, continued to explore how the protein’s shape related to its function for decades afterwards.
According to Alan Schechter, a physician-scientist and senior historical consultant at the US National Institutes of Health in Bethesda, the haemoglobin genes — more than any others at the time — offered “an entryway to understanding and perhaps treating a molecular disease”.
A sickle-cell researcher himself, Schechter says that such genes were a focus of conversation both at major genetics meetings and at blood-disease meetings in the 1970s and early 1980s. But as researchers gained access to new technologies for sequencing and manipulating DNA, they started to move on to other genes and diseases, including a then-mysterious infection that was predominantly striking down gay men.
Even before the 1983 discovery that HIV was the cause of AIDS, clinical immunologists such as David Klatzmann had noticed a peculiar pattern among people with the illness. “I was just struck by the fact that these people had no T4 cells,” recalls Klatzmann, who is now at Pierre and Marie Curie University in Paris. He showed
...
[Message clipped] View entire message
XXXXXXXXXXXXXXXXXX
He showed2 in cell-culture experiments that HIV seemed to selectively infect and destroy these cells, a subset of the immune system’s T cells. The question was: how was the virus getting into the cell?
Klatzmann reasoned that the surface protein (later called CD4) that immunologists used to define this set of cells might also serve as the receptor through which HIV entered the cell. He was right, as he reported3 in a study published in December 1984, alongside a similar paper4 from molecular virologist Robin Weiss, then at the Institute of Cancer Research in London, and his colleagues.
Within three years, CD4 was the top gene in the biomedical literature. It remained so from 1987 to 1996, a period in which it accounted for 1–2% of all the tags tallied by the NLM.
That attention stemmed in part from efforts to tackle the emerging AIDS crisis. In the late 1980s, for example, several companies dabbled with the idea of engineering therapeutic forms of the CD4 protein that could mop up HIV particles before they infected healthy cells. But results from small human trials proved “underwhelming”, says Jeffrey Lifson, director of the AIDS and Cancer Virus Program at the US National Cancer Institute in Frederick, Maryland.
An even bigger part of CD4’s popularity had to do with basic immunology. In 1986, researchers realized that CD4-expressing T cells could be subdivided into two distinct populations — one that eliminates cell-infecting bacteria and viruses, and one that guards against parasites such as worms, which cause illness without invading cells. “It was a fairly exciting time, because we really understood very little,” says Dan Littman, an immunologist at the New York University School of Medicine. Just the year before, he had helped to clone the DNA that encodes CD4 and insert it into bacteria5, so that vast quantities of the protein could be made for research.
A decade later, Littman also co-led one of three teams to show6that to enter cells, HIV uses another receptor alongside CD4: a protein identified as CCR5. These, and a second co-receptor called CXCR4, have remained the focus of intensive, global HIV research ever since, with the goal — as-yet unfulfilled — of blocking the virus’s entry into cells.
Fifteen minutes of fame
By the early 1990s, TP53 was already ascendant. But before it climbed to the top of the human gene ladder, there were a few years in which a lesser-known gene called GRB2 was in the spotlight.
At the time, researchers were starting to identify the specific protein interactions involved in cell communication. Thanks to pioneering work by cell biologist Tony Pawson, scientists knew that some small intracellular proteins contained a module called SH2, which could bind to activated proteins at the surface of cells and relay a signal to the nucleus.
In 1992, Joseph Schlessinger, a biochemist at the Yale University School of Medicine in New Haven, Connecticut, showed7 that the protein encoded by GRB2 — growth factor receptor-bound protein 2 — was that relay point. It contains an SH2 module as well as two domains that activate proteins involved in cell growth and survival. “It’s a molecular matchmaker,” Schlessinger says.
Other researchers soon filled in the gaps, opening a field of study in signal transduction. And although many other building blocks of cell signalling were soon unearthed — ultimately leading to treatments for cancer, autoimmune disorders, diabetes and heart disease — GRB2 stayed at the forefront and was the top-referenced gene for three years in the late 1990s.
In part, that was because GRB2 “was the first physical connection between two parts of the signal-transduction cascade”, says Peter van der Geer, a biochemist at San Diego State University in California. Furthermore, “it’s involved in so many different aspects of cellular regulation”.
GRB2 is something of an outlier in the most-studied list. It’s not a direct cause of disease; nor is it a drug target, which perhaps explains why its moment in the sun was fleeting. “You have some rising stars that fall down very quickly because they have no clinical value,” says Thierry Soussi, a long-time TP53 researcher at the Karolinska Institute in Stockholm and Pierre and Marie Curie University. Genes with staying power usually show some sort of therapeutic potential that attracts funding agencies’ support. “It’s always like that,” Soussi says. “The importance of a gene is linked to its clinical value.”
It can also be linked to certain properties of the gene, such as the levels at which it is expressed, how much it varies between populations and the characteristics of its structure. That’s according to an analysis by Thomas Stoeger, a systems biologist at Northwestern University in Evanston, Illinois, who reported this month at a symposium in Heidelberg, Germany, that he could predict which genes would garner the most attention, simply by plugging such attributes into an algorithm.
Stoeger thinks that the reasons for these associations largely boil down to what he calls discoverability. The popular genes happened to be in hot areas of biology and could be probed with the tools available at the time. “It’s easier to study some things than others,” says Stoeger — and that’s a problem, because vast numbers of genes remain uncharacterized and underexplored, leaving major gaps in the understanding of human health and disease.
Curry also points to “intertwined technical, social and economic factors” shaped by politicians, drugmakers and patient advocates.
XXXXXXXXXXXXXXXXX
Right place, right time
Stoeger has also tracked how the general features of popular genes have changed over time. He found, for example, that in the 1980s, researchers focused largely on genes whose protein products were found outside cells. That’s probably because these proteins were easiest to isolate and study. Only more recently did attention shift towards genes whose products are found inside the cell.
That shift happened alongside the publication of the human genome, says Stoeger. The advance would have opened up a larger percentage of genes to enquiry.
Many of the most explored genes, however, don’t fit these larger trends. The p53 protein, for example, is active inside the nucleus. Yet TP53 became the most studied gene around 2000. It, like many of the genes that came to dominate biological research, was not properly understood after its initial discovery — which may explain why it took several decades after the 1979 characterization of the protein for the gene to rise to the top spot in the literature.
At first, the cancer-research community mistook it for an oncogene — one that, when mutated, drives the development of cancer. It wasn’t until 1989 that Suzanne Baker, a graduate student in Vogelstein’s lab, showed8 that it was actually a tumour suppressor. Only then did functional studies of the gene really begin to pick up steam. “You can see from the spike in publications that go up essentially at that point that there were a lot of people who were really very interested,” says Baker, now a brain-tumour researcher at the St. Jude Children’s Research Hospital in Memphis, Tennessee.
Research into human cancer also brought scientists to TNF, the runner-up to TP53 as the most-referenced human gene of all time, with more than 5,300 citations in the NLM data (see ‘Top genes’). It encodes a protein — tumour necrosis factor — named in 1975 because of its ability to kill cancer cells. But anticancer action proved not to be TNF’s main function. Therapeutic forms of the TNF protein were highly toxic when tested in people.
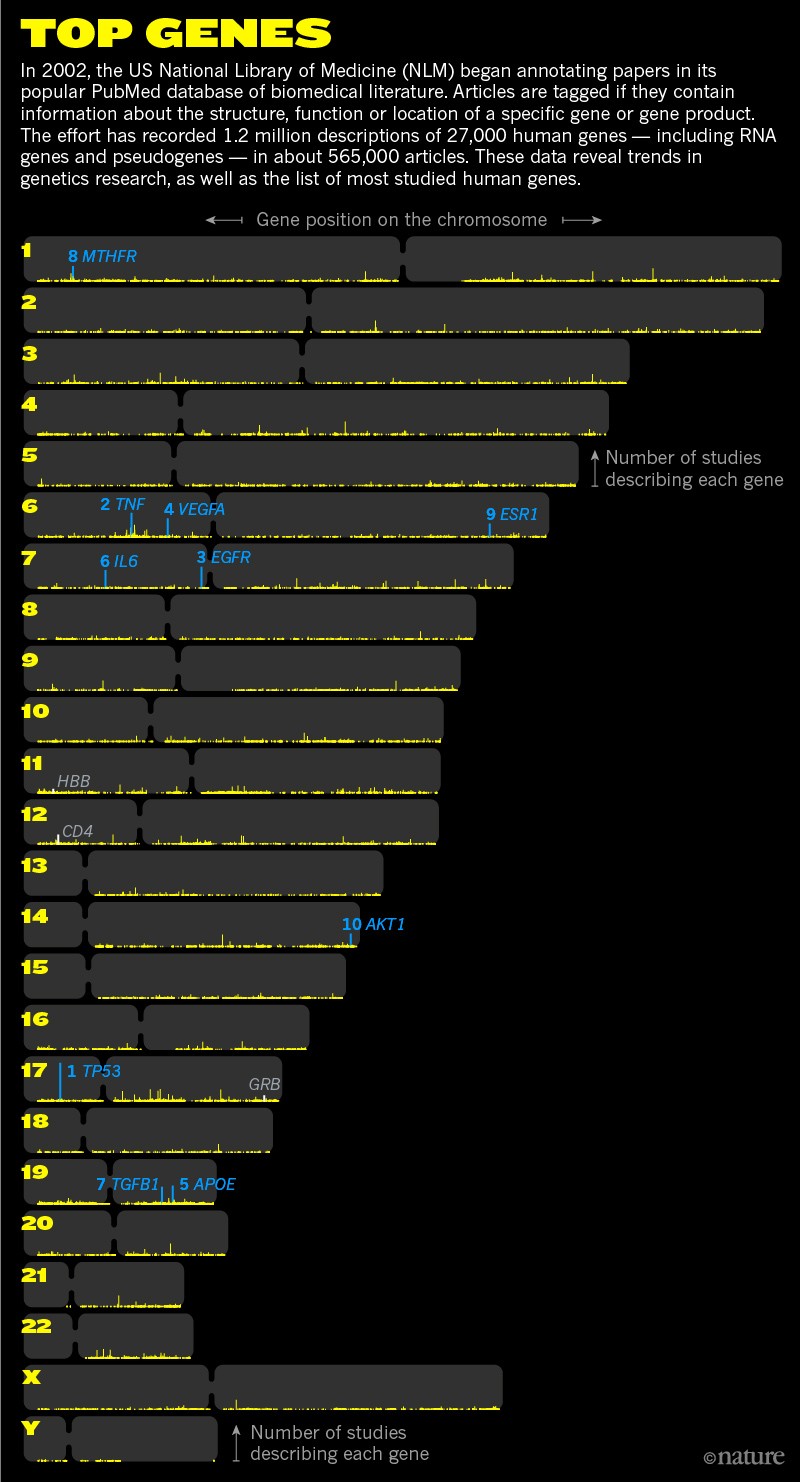
Source: Peter Kerpedjiev/NCBI-NLM
XXXXXXXXXXXXXXXX
The gene turned out to be a mediator of inflammation; its effect on tumours was secondary. Once that became clear in the mid-1980s, attention quickly shifted to testing antibodies that block its action. Now, anti-TNF therapies are mainstays of treatment for inflammatory disorders such as rheumatoid arthritis, collectively pulling in tens of billions of dollars in annual sales worldwide.
“This is an example where the knowledge of the gene and the gene product has relatively quickly changed the health of the world,” says Kevin Tracey, a neurosurgeon and immunologist at the Feinstein Institute for Medical Research in Manhasset, New York.
TP53’s dominance was briefly interrupted by another gene, APOE. First described in the mid-1970s as a transporter involved in clearing cholesterol from the blood, the APOE protein was “seriously considered” as a lipid-lowering treatment for preventing heart disease, says Robert Mahley, a pioneer in the field at the University of California, San Francisco, who tested the approach in rabbits9.
Ultimately, the creation of statins in the late 1980s doomed this strategy to the dustbin of pharmaceutical history. But then, neuroscientist Allen Roses and his colleagues found the APOE protein bound up in the sticky brain plaques of people with Alzheimer’s disease. They showed10 in 1993 that one particular form of the gene, APOE4, was associated with a greatly increased risk of the disease.
This generated much wider interest in the gene. Still, it took time to move up the most-studied chart. “The reception was very cool,” recalls Ann Saunders, a neurogeneticist and chief executive of Zinfandel Pharmaceuticals in Chapel Hill, North Carolina, who collaborated with Roses, her late husband. The amyloid hypothesis, which states that build-up of a protein fragment called amyloid-β is responsible for the disease, was all the rage in the Alzheimer’s-research community at the time. And few researchers seemed interested in finding out what a cholesterol-transport protein had to do with the disease. But the genetic link between APOE4 and Alzheimer’s risk proved “irrefutable”, Mahley says, and in 2001,APOE briefly overtook TP53. It remains in the all-time top five, at least for humans (see ‘Beyond human’).
BEYOND HUMAN
The US National Library of Medicine has tracked references to genes from dozens of species, including mice, flies and other important model organisms, as well as viruses. Looking at genes from all species, more than two-thirds of the 100 most studied genes over the past 50 years have been human (see ‘The gene menagerie’). But non-human genes do appear quite high on the list. Often, these have a clear link to human health, as with mouse versions of TP53, or env, a viral gene that encodes envelope proteins involved in gaining entry to a cell.

Source: Peter Kerpedjiev/NCBI-NLM
Like other popular genes, APOE is well studied because it’s central to one of the biggest unsolved health problems of the day. But it’s also important because anti-amyloid therapies have mostly flamed out in clinical testing. “I hate saying this, but what helped me were the failed trials,” says Mahley, who this year raised US$63 million for his company E-Scape Bio to develop drugs that target the APOE4 protein. Those failures, he says, forced industry and funding agencies to rethink therapeutic strategies for tackling Alzheimer’s.
There’s the rub: it takes a certain confluence of biology, societal pressure, business opportunity and medical need for any gene to become more studied than any other. But once it has made it to the upper echelons, there’s a “level of conservatism”, says Gregory Radick, a science historian at the University of Leeds, UK, “with certain genes emerging as safe bets and then persisting until conditions change”.
The question now is how conditions might change. What new discoveries might send a new gene up the chart — and knock today’s top genes off their pedestal?
doi: 10.1038/d41586-017-07291-9
XXXXXXXXXXXXXXX
eferences
- 1.Mitchell, J. A. et al. AMIA Annu. Symp. Proc. 2003, 460–464 (2003).
- 2.Klatzmann, D. et al. Science 225, 59–63 (1984).
- 3.Klatzmann, D. et al. Nature 312, 767–768 (1984).
- 4.Dalgleish, A. G. et al. Nature 312, 763–767 (1984).
- 5.Maddon, P. J. et al. Cell 42, 93–104 (1985).
- 6.Deng, H. et al. Nature 381, 661–666 (1996).
- 7.Lowenstein, E. J. et al. Cell 70, 431–442 (1992).
- 8.Baker, S. J. et al. Science 244, 217–221 (1989).
- 9.Mahley, R. W. et al. J. Clin. Invest. 83, 2125–2130 (1989).
- 10.Strittmatter, W. J. et al. Proc. Natl Acad. Sci. USA 90, 1977–1981 (1993).
- 11.Morgan, T. H. Science 32, 120–122 (1910).
- 12.Green, M. M. Genetics 184, 3–7 (2010).
- 13.Friedrich, G. & Soriano, P. Genes Dev. 5, 1513–1523 (1991).
XXXXXXXXXXXXXXXX



XXXXXXXXXXXXXXXXXXXXX
No comments:
Post a Comment